


A Comprehensive Guide to MapReduce: Distributed Data Processing
Understanding the motivation, how it works and real-world applications of MapReduce


In this article, I will explore the MapReduce programming model introduced on Google's paper, MapReduce: Simplified Data Processing on Large Clusters. I hope you will understand how it works, its importance and some of the trade offs that Google made while implementing the paper. I will also provide real world applications of MapReduce at the end of the article.
Motivation: the problem Google was facing
In 2004, Google needed a way of processing large data sets, theoretically, the whole web. Google's engineers faced the challenge of processing enormous datasets generated by their web crawlers, indexing systems, and various other applications. Traditional data processing systems couldn't handle the scale or the fault tolerance required for such large-scale operations, imagine having to sort or classify the whole web for example.
At that time, distributed computing was already a thing, so one of the first things that the engineers might have thought was, "let's distribute the workload across multiple computers". But the problem is that many engineers were not familiar with implementing distributed computing algorithms at the scale required by Google's operations, so they needed to have an abstraction for doing so. This is when MapReduce was designed by Jeffrey Dean and Sanjay Ghemawat.
Before moving on, if you want to learn more about distributed computing/distributed systems, you can read Distributed Systems 101 (based on Understanding Distributed Systems book) for an introduction to the topic.
How MapReduce works: solving the problem of processing the whole web
MapReduce is a programming model for processing and generating large data sets. Users specify a Map function that processes a key/value pair to generate a set of key/value pairs, and a Reduce function that merges all values associated with the same key.
Take for example a word count, where you receive a text as a input and need to count the occurrences of each word on the text (you can see a representation of this on the image below).
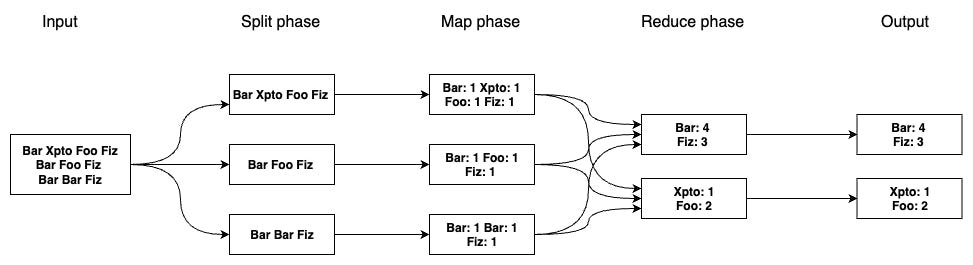
The MapReduce will...
Split the input into many chucks in order to run the operation on multiple machines
Map the input data in order to generate a set of key/value pairs
- On the Map phase, we have many machines processing part of the input that was Split before (remember that we have a large input, like the whole web, so it is inefficient to do it on a single machine)
Reduce the key/value pairs by merging them based on their keys
- Since we are performing a word count here, the Reduce function sums each value based on the key. Each Reduce function writes the result to a file
The final output consists of unique keys and their corresponding reduced values.
The coordinator
In order for the MapReduce to function, there needs to be something coordinating all of this. We want to be able to just pass the input to it and let it run without worrying about its internal details. The component that receives this first input and starts the whole operation is called coordinator. The coordinator is responsible to pass the chunks for the machines to run the Map, that means that the coordinator is responsible for Splitting the data.
When a machine finishes the Map phase, it notifies the coordinator and passes the location of the finished Map result file to it. Then the coordinator calls the Reduce function on another machine with the location of the file to perform the reduce on. This implies on the machine responsible to execute the Reduce to access the machine that did the Map previously.
As seen before, when a machine finishes the Reduce phase, it writes the result to a file, the coordinator then returns these files to the MapReduce caller. It is important to notice that the files doesn't really needs to travel through the network, although they are reduced, they could still be big enough to impact performance significantly. What can be done here, depending on the implementation of the coordinator, is returning the address where the reduced files are stored.
Network bandwidth is a problem (one of the biggest)
The first fallacy of distributed computing is, "The network is reliable". That means that we want to minimize the traveling of the data through the network. Google does so by storing the inputs of the the Map phase on the same machines that executes the Map.
We can take a web crawler as an example, when the crawler finishes crawling a page, it can write a file on the same machine that will execute the Map phase on this file. The same applies to the Reduce function result, in which the files that each reducer wrote aren't concatenated or even passed through the network until they really need to get read, only their addresses are shared until then.
Fault tolerance importance in MapReduce
Fault tolerance is a critical aspect of distributed computing, and MapReduce is no exception. Ensuring that the system can gracefully recover from failures is essential for handling large-scale data processing tasks reliably.
How MapReduce is fault tolerant?
MapReduce ensures fault tolerance by running multiple instances of the same task across different machines. By doing so, if one machine fails during execution, the task can be rerun on another machine without data loss. The coordinator plays a role here by continuously monitoring the machines executing the processes. In the event of a machine failure, the coordinator reallocates the task to another operational machine that has already completed its previously assigned task.
Since the inputs are stored on the same machines that are responsible for the Mapping, copies of the same input must be stored on different machines, so that if one fails, the coordinator can use the others with the same input to execute the task. In fact according to the MapReduce paper, Google stores typically 3 copies on different machines.
Idempotency is also very important in MapReduce systems. Both Map and Reduce tasks are designed to be idempotent, meaning they can be run multiple times without altering the final result. This ensures consistency and reliability, especially in scenarios like the one above, where some tasks needs to be rerun due to failures.
The coordinator can't fail
All that we talked about regarding fault tolerance here pertains to the machines that perform the Map and Reduce functions, but there is one more piece, which is the coordinator. Google itself decided not do make the coordinator fault tolerance, because it is more likely that one of the 2000 machines that runs the "Map" will crash instead of that one single machine that runs the coordinator for example. Here we see a trade-off between complexity and likelihood of failure.
Real-world applications of MapReduce
There are many applications in which MapReduce can be useful, below only a few of them are listed, but MapReduce can (and is) used on a widely range of real world applications. It is also important to keep in mind that it is designed for processing large datasets in which it wouldn't be efficient processing it on only a single machine for example.
Counting URL Access Frequency: in this scenario, the Map function processes logs of web page requests, extracting URLs and emitting key-value pairs, like (url, accessCount). The Reduce function aggregates the counts for each URL, producing a final output of unique URLs and their corresponding access frequencies.
Data Cleaning and Preprocessing: MapReduce can be used to clean and preprocess large datasets before further analysis. For example, the Map function can perform tasks such as data validation, transformation, and filtering, while the Reduce function can aggregate the results and produce a cleaned dataset ready for analysis.
Log Analysis: logs can be collected from servers, applications, and network devices to monitor system health, troubleshoot issues, and gain insights into user behavior. With MapReduce, those logs can be processed in parallel across multiple machines, the Map function can parse each log entry and emit key-value pairs based on the information extracted, while the Reduce function can perform analyses on this data, like counting the most common types of errors for example.
This is the end of the article, but not the end of our journey on distributed systems, feel free to leave any comments or suggestions. Here are some next steps, such as papers and books, that you can explore to gain a deeper understanding of distributed processing of large datasets:
MapReduce: Simplified Data Processing on Large Clusters (paper that introduces the MapReduce programming model)
Bigtable: A Distributed Storage System for Structured Data (paper about a distributed storage system designed to handle massive amounts of structured data across thousands of servers)
Building and operating a pretty big storage system called S3 (article about AWS S3 written by a distinguished engineer at AWS)
Designing Data-Intensive Applications (book by Martin Kleppmann that covers the principles of building distributed applications)